How COPPER works
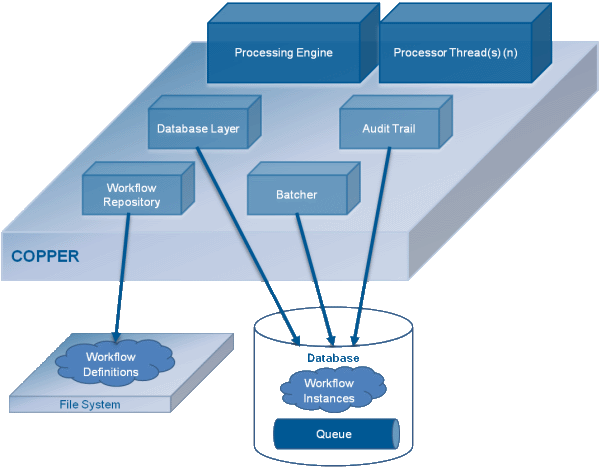
COPPER Components
Processing Engine
- Main entity in the COPPER architecture that executes workflow instances
- Runs in a single JVM process
- Supports transient and persistent workflows
Workflow Repository
- Encapsulates the storage and handling of workflow definitions
- Reads workflow definitions from the file system
- Hot Deployment: Observes file system for modified files
Database Layer
- Decouples COPPER core components from the database
- Encapsulates the access to persistent workflow instances and queues
- Enables implementation of customised database layers, e.g. with application-specific optimisation or for yet unsupported DBMS
Audit Trail
- Implements simple and generic audit trail
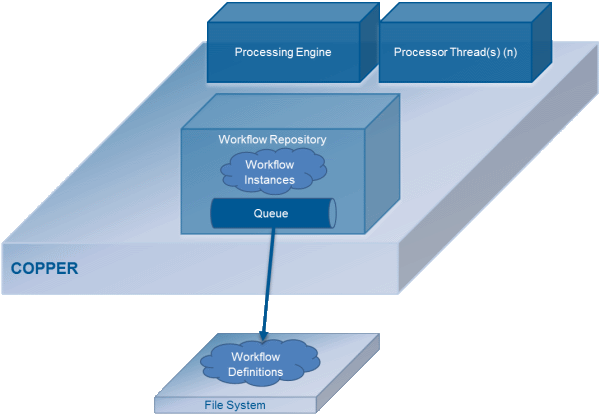
Transient workflows
Transient workflows are often used for processing read-only requests or in cases where it is sufficient for the workflow processes to reside in the system main memory.
Persistent Workflows
Persistent workflows are stored in the database. They are typically used in the following situations:
Long-running Tasks
Workflow instances exist over a longer time period such as days, weeks, or even months. In such cases, the workflow instances must survive the starting and stopping of the application.
Crash Recovery
In case of a crash recovery, the affected workflow instances must be restored. To enable this, so-called checkpoints are written to the database.
High Availability/ Load Distribution
COPPER runs in a distributed environment. Multiple copper engines, running on different nodes, are then coupled to a cluster. This offers high availability, load distribution and automatic failover in case that one or more nodes should crash. Please note that this feature requires a high availability database system, e.g. Oracle RAC.